

Pythonは学習コストが低く、AIやWeb、スクレイピングなど幅広い分野で使われていますが、処理速度が遅いという課題があります。
この記事では、Pythonコードを高速化するために知っておくべき7つのポイントを、「なぜそれが効果的なのか」に焦点を当てて解説します。
1. NumPyを使ったベクトル化でループを撃退
◆ なぜ速くなるのか?
通常、Pythonでリスト内の値を合計するにはforループを使いますが、これはインタプリタが1行ずつ実行するため非常に遅いです。NumPyはCで実装されており、**内部的に処理を一括して行うベクトル化(SIMD的処理)**が可能なため、ループ不要で高速に動作します。
◆ ベクトル化の例(概念)
- Pythonのループ:
for文で1要素ずつ操作 - NumPy:すべての要素に対して同時に処理
2. スコープを意識してローカル変数を活用する
◆ なぜ速くなるのか?
Pythonは、変数のスコープ(有効範囲)に応じてアクセスコストが変わります。
- ローカル変数:最も高速(スタックにある)
- グローバル変数:辞書から探索されるため遅い
- ビルトイン変数:さらに探索階層が深い
ローカル変数に代入してから使うことで、繰り返しアクセスのコストを削減できます。
3. 組み込み関数を活用する
◆ なぜ速くなるのか?
Python標準の組み込み関数(sum, min, max, sortedなど)は、C言語で書かれており、最適化済みです。これらを使うことで、同じ処理でもPythonでforループを書くよりはるかに高速に処理できます。
◆ よく使う高速な組み込み関数
sum(list)any(),all()enumerate(),zip()sorted()
4. リスト内包表記で高速にリスト生成
◆ なぜ速くなるのか?
リスト内包表記(List Comprehension)は、Pythonの内部処理が最適化されており、append()付きのforループと比べて最大30%以上高速になるケースもあります。変数スコープが局所的に閉じていることも、速度の要因の一つです。
# 遅い方法
result = []
for x in range(1000):
result.append(x * 2)
# 速い方法
result = [x * 2 for x in range(1000)]5. in の対象を集合や辞書にする
◆ なぜ速くなるのか?
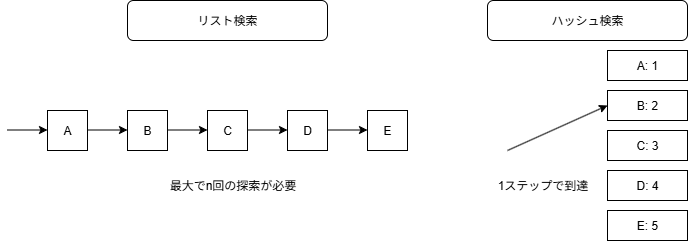
x in list でリスト内を検索すると、先頭から末尾まで順に探索されるため、要素数が増えるとどんどん遅くなります(O(n))。一方、x in set や x in dict は**ハッシュテーブルで探索(O(1))**するため、要素数に依存しない高速検索が可能です。
6. 不要な処理を避け、早めに抜ける(早期リターン)
◆ なぜ速くなるのか?
多くの処理は、全部の条件をチェックする必要はない場合が多いです。例えば、特定条件が満たされたら**returnで即終了**することで、それ以降の無駄な処理を避けられます。
◆ 例
def process(item):
if not item:
return # 早期終了で無駄な処理を防ぐ
# 後続処理(時間がかかる)◆ その他の無駄削減方法
- 不必要なprint文を削除
- 大きな関数を分割し、無駄な分岐を避ける
7. JITコンパイラ(Numba, Cython)を導入する
◆ なぜ速くなるのか?
Pythonはインタプリタ型の言語ですが、JIT(Just-In-Time)コンパイラを使うことで、動的にCレベルのコードへ変換して高速化が可能になります。
◆ 代表的なJITツール
- Numba:関数に
@jitデコレータを付けるだけでOK。NumPyとの相性抜群。 - Cython:Pythonコードに型を付けてCに変換。高度な最適化が可能。
+α:さらに高速化を目指すなら?
🔍 プロファイラでボトルネックを特定しよう
cProfileやline_profilerなどを使うと、どこで時間がかかっているかが可視化できます。- 無闇に高速化するより、まず「重い部分」を知るのが最短の近道です。
🧵 並列化や非同期処理の検討も視野に
- 並列処理:
multiprocessing,joblib - 非同期処理:
asyncio,aiohttp - I/Oがボトルネックなら非同期、計算が重ければ並列化が有効です。
まとめ:Pythonは遅いけど工夫次第で十分速くなる
| 方法 | なぜ効く? |
|---|---|
| NumPyでベクトル化 | C実装による一括処理 |
| ローカル変数を使う | スタックアクセスで高速 |
| 組み込み関数を使う | 最適化されたC実装 |
| リスト内包表記 | 無駄な関数呼び出しを省略 |
| set/dictで検索 | O(1)の高速ハッシュ検索 |
| 早期リターン | 無駄な計算を避けられる |
| JIT(Numba/Cython)導入 | Cレベルで実行される |
🔗 参考
- Qiita: Pythonを高速化する7つの方法
- Python公式ドキュメント: Built-in Functions
- Numba公式: https://numba.pydata.org
- Cython公式: https://cython.org

